
Go 1.26
The new release is not headline-grabbing, but I have been playing with the beta and release candidate (esp. new SIMD stuff) since before Christmas and there is some very cool stuff, especially if performance is important to you.
The new garbage collector, which I discussed in detail last time, is now the default. It is good (but if you suspect it is causing issues you can still revert to the previous one).
As well as these I’ll look at these things:
- the built-in function
new()has a useful overload - generic types can now refer to themselves
- goroutine leaks can be found using a new profiler
- go fix has been rewritten (in preparation for Go 2.0? ;)
- standard library additions for performance and security
But my favourite addition is the archsimd package that makes using SIMD instructions easy to use. I did a lot of tests of this and found that it can boost performance up to 20 times!
Unfortunately, archsimd currently only supports amd64 (Intel/AMD). I’ll undoubtedly look at it again when it supports other architectures (like ARM) and hopefully some sort of high-level “architecture independent” package.
Background
General
What is SIMD?
SIMD stands for single instruction - multiple data. It means there is a single CPU instruction that can simultaneously perform the same operation on an array or “vector” of operands of the same type.
If you think about it, all computers have SIMD instructions. When a CPU performs bitwise operations (AND, NOT, etc) it is performing the same operation on each bit. A 32-bit integer is effectively a “vector” of 32 booleans – like [32]bool in Go but packed into an int32.
However, SIMD conventionally refers to vectors of numbers. Supercomputers of the past had SIMD instructions for vectors of floating point numbers. This was used for linear algebra used in scientific/engineering software such as modelling of the climate, nuclear explosions, aerodynamics, etc.
Then, almost 30 years ago SIMD instructions started appearing on microprocessors too. These initially worked with integers and were intended for “multimedia” applications (but, I believe, the main driver was games :) for 3D graphics, video, sound etc. They later supported floating-point but are now used in all sorts of applications like image processing, encryption, AI, …
Meanwhile, GPUs matured to take some of the SIMD load off the CPU and are now used for many of the same things (not just 3D graphics which they were originally meant for).
X86 SIMD Instructions
Starting with Intel’s MMX instructions there have been many (at least a dozen) SIMD instruction set additions from Intel (and some from AMD). This means you need to carefully check what CPU you are using and/or special CPU flag bits before you use any SIMD instruction.
1997: MMX (multimedia extensions) added 8 (64 bit) registers for integer (8/16/32) operations but these were aliases for the floating point registers making them very tricky to use.
1999: SSE (streaming SIMD extensions) added separate (128 bit) registers (XMM0-XMM7) which could be used for 2 x float64, 4 x float32, 2 x int64, etc. AMD (and later Intel) added XMM8-XMM15 registers but only in 64-bit mode.
200X: There were later additions designated SSE2, SSE3, SSE4a, SSE4.1, SSE4.2
2011: AVX (Advanced Vector Extensions) added 256-bit registers (YMM0-YMM15) where the lower 128 bits were XMM0-XMM15.
2013: AVX2 added more instructions. Most X86 computers nowadays have this.
2016: AVX-512 added 512-bit registers ZMM0-ZMM31 (including lower bits in YMM16-31, XMM16-31)

Not shown here is eight special mask registers (vector of up to 64 bits) called K0-K7. These were added in AVX-512, but I’m not going to look at them preferring to concentrate on AVX2.
2023: AMX added matrix registers (TMM0-TMM7) and matrix multiplication
2024+ AVX10.X 8-bit floats etc
See List of x86 SIMD instructions for details
Note that AVX-512 also supports 16-bit floats but Go does not support that (yet?). Go will probably never have a float16 type unless it appears in most/all architectures, but FP16 is currently supported by the Go library of Apache Arrow.
SIMD in Use
Many compilers that target the X86 instruction set nowadays will use some SIMD instructions for convenience or for a small performance improvement.
There have also been more valiant attempts to “auto-vectorise” loops. The compiler will detect a loop that is performing an operation on a vector and try to convert it into the equivalent SIMD instructions. But this is difficult and not very successful.
Since “auto-vectorisation” is not that useful, those interested in performance will often resort to assembler to use SIMD. C++ compilers (and recently other languages) have added SIMD using intrinsics where you would use a SIMD instruction much like you would call a function.
Personally, I have found SIMD intrinsics in C++ cumbersome. I used them in my hex editor (more than a decade ago!) to speed up operations like mass bitwise operations (eg see HexEditView.cpp).
The approach that Go has taken shows great promise, but we will see how it goes.
ARM et al
I have concentrated on the X86 architecture, as it was the first and seems to have the most SIMD support. Other important architectures also have SIMD instructions like ARM Neon. I don’t know much about those, but I believe they take a different (variable length vector) approach.
Go
Go Assembler
Using SIMD in Go, until now, required using assembler (aka assembly code). Unfortunately, using assembler from Go is not well-supported. For example, there is no way to have assembler code inlined. See The problem with the current assembly support for more.
Go SIMD Proposals
There have been many requests and proposals for adding SIMD support to Go, going back almost to its inception. For example, see this Golang nuts post from 2014.
It’s great to see that something is now happening and I think it has been worth the wait.
Future of SIMD in Go
First, given the difficulty of “auto-vectorising” loops, and the lack of success over many years of trying, I don’t think this will be attempted for Go in the foreseeable future.
So it will be left to the gophers (users of the language) to understand how to use SIMD. Luckily for us, it seems that using SIMD in Go might be far less tedious than in other languages.
As often happens, the Go developers have learnt a lot from other languages and from research projects (especially Google’s). Apparently Go SIMD support is taking a lot of inspiration from the success of the Highway C++ library.
Highway makes it possible to create software that works across platforms. It even supports variable length vectors used in ARM and RISC-V architectures. Moreover, you don’t have to know anything about the hardware as dynamic dispatch automatically selects the best performing instructions available.
Hopefully, Go will one day even support SIMD on WASM.
It’s All About the Cache
I love that there’s been lots of performance improvements in recent Go releases. What is not obvious (or even stated AFAIK) is that the major driver has been better use of CPU caches.
Go 1.21 added PGO which does a lot of things to assist the instruction (and data) caches. Maps are used a lot in Go and 1.24 completely refactored them with Swiss Tables which are more cache friendly - much like the new Green Tea GC.
Also in Go 1.24 there were changes to sync.Mutex which prevents too many cache stalls for high-contention mutexes.
In this release the changes to heap data structures (GTGC), and SIMD (indirectly), benefit from the cache.
Latency due to GC
I talked about latency problems when Go’s garbage collector is running last time - see Garbage Collection.
There have been lots of complaints about Go’s GC in the past, but they have generally all been resolved now for a few years. I looked at them in detail last time – see the Background->Garbage Collection->Latency Issues.
My suspicion was always that, at least partly, latency problems were due to the way GC memory distribution affects data cache use. GTGC has reduced latency problems even further by allocating memory in a more cache friendly way.
Standard Library
SIMD (Experiment)
SIMD (single instruction-multiple data) refers to a special class of CPU instructions that have appeared over time in microprocessor instruction sets. They let you perform the same operations on an array or “vector” of values (integer or float) in about the same time it would normally take to operate on a single value.
If you can find a way to use them you might find a huge speed improvement which can be crucial for low-level “hot” functions.
SIMD Uses
SIMD has esoteric uses that have become important in areas such as 3D graphics, AI, encryption, modelling, etc. In particular, a lot of scientific and technical software uses linear algebra.
SIMD instructions are now ubiquitous in high-end CPUs. They are often used in unexpected areas. For example, the new Green Tea GC (see below) uses SIMD instructions to improve speed of garbage collection.
Most modern compilers (or their code-generation back end) will make use of SIMD instructions, if supported by the instruction set they are generating for. When you use Go you are (depending on the architecture) perhaps already using SIMD instructions.
However, compilers don’t get the best out of SIMD. SIMD shines when you are performing the same operations on a vector – normally done in a loop – as long as each iteration is independent of the previous one. Some compilers try to detect such loops and convert them to SIMD instructions, but currently “auto-vectorisation” has limited use.
❝ auto-vectorisation has limited use ❞The Go compiler does not do this.
Why do I need it?
Compilers aren’t good at auto-vectorisation and the Go compiler doesn’t even try. It is up to you to understand how you can use SIMD in your code. I’ll give a few examples to show what is possible.
Note that, until now, you had to use assembler in Go and even then there were limitations (see Background above). It’s about time - other languages have some support, even JS!
Using SIMD in Go 1.26
Go (as usual :) makes things simple. You import simd/archsimd and use its types and their methods. The types represent SIMD registers, operations are implemented as methods so you can easily chain them like this: vector.Add(vector2).Mul(vector3).
Although archsimd just appears to be a simple package, but there is also SIMD support built into the compiler. Consecutive operations are efficiently performed in SIMD registers without involving memory. You can see how each operation generates a single assembler instruction in the (Compiler Explorer) screenshot below.
To enable the simd/archsimd package in Go 1.26, you must set the simd experiment – ie, set the environment variable GOEXPERIMENT=simd. It’s currently only useful for Intel/AMD “X86” processors (GOARCH=amd64).
As a simple example, here is a function that operates on three arrays (of 32 bytes) returning an array of the result (addition of corresponding array elements). On my machine this (no SIMD) loop takes about 27 nsecs to run.
func Add3(x, y, z [32]int8) (r [32]int8) {
for i := range x {
r[i] = x[i] + y[i] + z[i]
}
return
}
Doing the same thing with SIMD takes about 7 nsecs.
import "simd/archsimd"
...
func Add3(x, y, z [32]int8) (r [32]int8) {
xvec := archsimd.LoadInt8x32(&x)
yvec := archsimd.LoadInt8x32(&y)
zvec := archsimd.LoadInt8x32(&z)
result := xvec.Add(yvec).Add(zvec)
result.Store(&r)
return
}
Moreover, the actual line that does the work (using the two calls to the Add() method) generates just 2 SIMD instructions and runs in less than 2 nsecs.
A great way to see the SIMD instructions generated by the Go compiler is to use Matt Godbolt’s Compiler Explorer. Try the above code now with this link: Add3 in Compiler Explorer.
To manually set the options of Compiler Explorer: select Go language with compiler version x86-64 gc 1.26.0 + set the environment variable GOEXPERIMENT=simd using the Overrides (spanner) button.
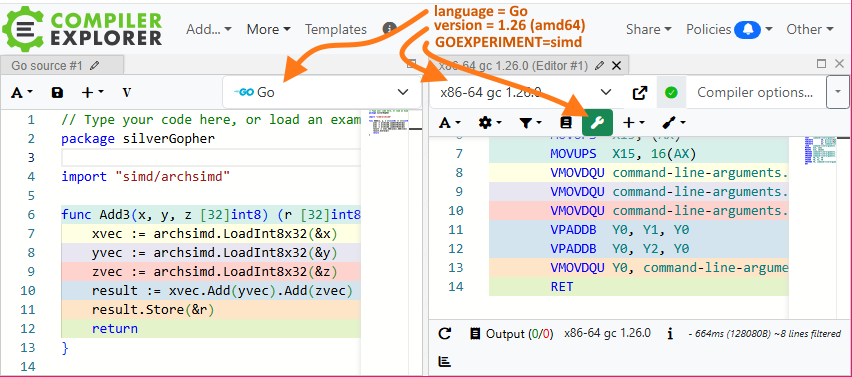
I also turn off CE’s auto-compile option (which I find annoying) by unchecking More/Settings/Compilation/Compile Automatically when source changes. Then you just hit Ctrl+Enter to compile the code (or right-click and select Compile from the context menu).
Benchmarks
[ED(26/04/13): added this section by request]
Here is the benchmark code that I used to get the above timings.
func BenchmarkAdd3(b *testing.B) {
x := [32]int8{0, 0, 0, 0, 0, 0, 0, 0, 0, 127, -127, 127, 127}
y := [32]int8{1, 2, 3, 4, 5, 6, 7, 8, 9, 127, 127, -128, 1}
z := [32]int8{1, 2, 3, 4, 5, 6, 7, 8, 9, 127, 127, -128, 1}
var result [32]int8
for b.Loop() {
result = Add3(x, y, z)
}
fmt.Println(result)
}
This gave 27ns/op using the first (loop) version of Add3() vs 7ns/op (SIMD). I removed the SIMD instructions (result := xvec.Add(yvec).Add(zvec)) from Add3() to show that the load/store was taking 5ns/op, implying the SIMD instructions take about 2ns.
This might be even faster if Add3() is inlined. As I mentioned before in Go 1.24 Benchmarks the new b.Loop() prevents inlining of top-level functions.
Be careful benchmarking on a laptop. SIMD instructions can generate a lot of heat and might cause core(s) to be throttled.
SIMD Types
As explained in the Background section above, SIMD X86 instructions use special registers, of 128, 256 or 512 bits. For each SIMD register size Go has a type that supports eight different integer types (int8, uint8, int16, …, uint64) and two floating point types (float32 and float64). That is, there are 30 SIMD numeric “vector” types: 3 different register sizes which can store 10 different arithmetic types.
Remember, that there are only three different sizes of SIMD registers. The different Go types (e.g. for AVX2 256-bit registers) just determine which operations can be used - the Int8x32.Add() method generates the VPADDB instruction whereas Int16x16.Add() method generates VPADDW. Bitwise ops, by their nature, do not differentiate between these types - Int8x32.Or(), Int16x16.Or(), etc all generate VPOR.
| BITS | Integer | Unsigned | Float | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 128 | int8x16 | int16x8 | int32x4 | int64x2 | uint8x16 | ... | uint64x2 | float32x4 | float64x2 |
| 256 | int8x32 | int16x16 | int32x8 | int64x4 | uint8x32 | ... | uint64x4 | float32x8 | float64x4 |
| 512 | int8x64 | int16x32 | int32x16 | int64x8 | uint8x64 | ... | uint64x8 | float32x16 | float64x8 |
NOTE: AVX-512 also supports 16-bit floats but Go does not support a float16 type (yet?).
As well as the above types that represent the SIMD registers as vectors of numbers, there are also “mask” types that represent the registers as vectors of boolean values, because some SIMD operations produce boolean results. Since the “boolean” result it stored in the vector of the same size each value uses all bits on for true (and all bits off for false).
As an example, is you use a SIMD Add instruction you will get a vector of numbers as the result, but if you use a SIMD comparison instruction you will get a result as a mask type, where each element has either all bits on (for true) or all bits off. There are operations to convert such masks to corresponding integers – e.g. archsimd.Mask8x32.ToBits() converts 32 mask values (each with a value of 0x00 or 0xFF) to a uint32, with corresponding bits set/cleared.
| BITS | Mask | |||
|---|---|---|---|---|
| 128 | mask8x16 | mask16x8 | mask32x4 | mask64x2 |
| 256 | mask8x32 | mask16x16 | mask32x8 | mask64x4 |
| 512 | mask8x64 | mask16x32 | mask32x16 | mask64x8 |
Masks can also be used with bitwise operators (AND, OR, NOT), as we will see below, when vectorising loops that require branches.
AVX-512 added “mask” registers for vectors of one bit, for the result of operations that give a boolean result and to support masked operations. These are not supported in Go.
In summary: even though there are only currently only 3 different types of SIMD registers for the X86 architecture, there are 42 different Go types to handle them. All these types may seem unnecessary, but it actually makes for greater type safety and simpler code-completion.
SIMD Operations
There are many different SIMD operations. Some are just vector analogues of normal operators like + (Add()), & (And()), and == (Equal()). Others are esoteric and probably not of interest to most people (e.g. RoundToEvenScaledResidue()). Here I’ll only look at a few that are SIMD specific and generally useful.
Load and Store
As we saw in the above code example, there are functions/methods to load/store from/to slices and arrays, LoadInt8x32() creates an Int8x32 vector from an [32]int8 and Int8x32.Store() does the opposite. You can also work with slices: LoadInt8x32Slice() creates an Int8x32 vector from an []int8 but panics if the slice is not big enough, else you should use LoadInt8x32SlicePart().
You may wonder why Go doesn’t just provide SIMD operations that work directly on types like [32]int8. There are a few reasons but, to me, the main one is that it’s more obvious what is happening under the hood. The archsimd types effectively represent registers and this allows you to control when the SIMD registers are loaded and saved to memory. This makes it clear what is happening without looking at the assembler.
Sometimes you want to load the same (scalar) value into all elements of a vector. By convention to clear a vector (set it to zero) you would XOR it with itself (eg vec = vec.Xor(vec)) and to set all bits of a vector on you compare it to itself (then cast back from a mask as explained below - e.g. vec.Equal(vec).ToInt8x32()). To set all elements of a vector to any value you can use broadcast operations.
vec := archsimd.BroadcastInt8x32(42) // all bytes set to 42
Bitwise and Masked Operations
Arithmetic operations have multiple variations for different vector element sizes but bitwise operations (AND, NOT, XOR, etc) use the same instruction for all methods for the same vector size. For example, Int8x64.Xor(), Int16x32.Xor(), etc all compile to the same VPXOR instruction.
Bitwise operations can be used with masks to vectorise loops with branches. For example, the function below modifies all the values in an array by doubling them if less than the “cut-off” value or just adding it if above.
// DoubleCutoff doubles the values if less than "cutoff" else it is just added
func DoubleCutoff(a []int16, cutoff int) {
c := int16(cutoff)
for i := 0; i < len(a); i++ {
if a[i] < c {
a[i] *= 2
} else {
a[i] += c
}
}
}
Here is the same function using SIMD. The mask vector is used to determine which elements are doubled or have cutoff added. Each operation is performed on both vectors and a bitwise AND with the mask zeroes out the elements that are not needed, then the two results are ORed to get the final result.
func DoubleCutoff(a []int16, cut int) {
in := archsimd.LoadInt16x16Slice(a) // VMOVDQU
c := archsimd.BroadcastInt16x16(int16(cut)) // VBROADCASTW
mask := in.Less(c).ToInt16x16() // VPCMPGTW
double := in.Add(in).And(mask) // VPADDW, VPAND
add := in.Add(c).AndNot(mask) // VPADDW, VPANDN
// "OR" the 2 vectors to get the result and save it
double.Or(add).StoreSlice(a) // VPOR, VPMOVDQU
}
Conversions
As we saw in the tables above Go has several types that just represent the same SIMD registers in different ways. You can easily convert between these types using “As” methods – for example Int8x32 has methods like AsFloat64x4, AsFloat32x8, etc to convert to the other types that use a 256-bit register. These operations don’t generate any code; they just let the compiler view the bits in a different way. I have not found a use for them, especially as they bypass type safety,
However, you may need to bypass the type system when using masks. Comparison methods (like Greater()) produce a mask result (like Mask16x16) which you might then need to convert back to a numeric vector (like Int16x16) - e.g. see the use of Mask8x32.ToInt16x16() in the 4th line of the above example).
There are also real conversions between numeric types, that generate SIMD instructions. For example, Float64x4.ConvertToFloat32 converts a Float64x4 (256 bits) to a Float32x4 (128 bits). There are similar methods to convert between floats and signed/unsigned integers.
Saturated Operations
When you perform an integer operation that overflows you should already know that in Go the value simply wraps around. So uint8(255) + 2 will overflow the maximum size of a uint8 giving the value 1. In some languages overflow can also cause an exception (panic).
Saturation is an alternative where the value is “clamped” to the maximum (or minimum) allowed value. Saturated operations were initially added to SIMD for multimedia processing (images, video, sound – but really mainly for better performance in games!). For example, if you increase an image brightness past it’s maximum you don’t want it to go black, or if you increase the volume of sound samples you don’t want them to go very quiet.
x := archsimd.LoadInt8x32SlicePart([]int8{126, 127, -127, -128})
y := archsimd.LoadInt8x32SlicePart([]int8{9, 9, -9, -9})
result := x.AddSaturated(y) // 127, 127, -128, -128, ...
Alignment and Length
[ED(2026/04/18): A couple of things I meant to mention]
When using SIMD operations on an array, it’s important to consider the location (alignment) and length of the array.
Alignment
Loads from and stores to SIMD registers are faster if they are on a register size boundary. It might also help if they do not straddle a cache-line (ie, 64 byte boundary).
Unfortunately, Go has no simple way to allocate memory with suitable alignment. Memory allocated for Go objects, depending on what they contain, will be appropriately aligned (on 8, 16, 32 or 64-bit boundaries) but SIMD registers prefer alignment of 128, 256 and 512-bit (16,32,64 bytes).
The common way to handle this is to allocate slightly more memory than required and ignore the start. For example, if using archsimd.Int8x32 you can get a properly aligned slice like this:
func MakeSliceForInt8x32(size int) []int8 {}
reg_size := archsimd.Int8x32.Len() // 32
buf := make([]int8, size+(reg_size-8)) // slice of desired size + a bit extra
rem := int(uintptr(unsafe.Pointer(&buf[0]))) % reg_size
start := (reg_size - rem) % reg_size
return buf[start : start+size]
}
Alternatives include ignoring the problem and just load from badly aligned address. This is not recommended as the SIMD loads/stores will be slower for the whole array.
Or you could just process the start of the array using non-SIMD code. See the discussion in Non-SIMD Code below.
Length
The other issue you might need to handle is when the length of the array is not a multiple of the vector size. In this case you can either:
- allocate longer arrays with dummy elements at the end
- use non-SIMD code for elements at the end of the array
The first approach is simpler as you don’t need a “non-SIMD” version of the code, but are there any problems with it?
First, you will use a little bit more memory for the extra dummy values past the end of the array. There is also a bit of unnecessary processing done past for these dummy elements, but this will not affect performance as SIMD instructions operate on all elements in parallel.
However, I prefer the second solution as it is useful to have the non-SIMD code available.
Non-SIMD Code
I believe it is preferable to always have the non-SIMD code available for a few reasons:
- can be used to process the start of an array for badly aligned arrays
- process the end of an array if it’s not a multiple of the register size
- can be used for architectures that do not support SIMD
- can be used when the CPU does not support all the SIMD instructions
- can be used in tests to verify consistent result
TODO: code example
Build Considerations
Since archsimd currently only supports Intel/AMD instructions it is recommended that you use build tags to ensure that the compiler only builds the code for amd64 architecture. You can do this by including the build tag at the start of your source file:
//go:build amd64
package ...
func example(vec []int8) int {
// using SIMD
}
or, preferably, using a file name that ends in _amd64.go such as wxample_amd64.go.
See the relevant section in my blog on build tags Targeting OS/ARCH
Of course, if you also build for other architecture(s) you need the equivalent code in your package for those architecture(s) to avoid linking errors. You could use a separate file for each architecture such as example_arm.go, example_wasm.go, etc. More likely, you would just have a single file (perhaps called example_nosimd.go) with a !amd64 build tag:
//go:build !amd64
package ...
func example(vec []int8) int {
// not using SIMD (slower)
}
If you try to use archsimd with an earlier Go version or without the simd experiment turned you will also get build errors that might be confusing. To make it clear what is needed for your code to build you should probably use three build tags:
//go:build amd64 && go1.26 && goexperiment.simd
package simdTest
import "simd/archsimd"
Runtime Considerations
As explained in the background section above not all SIMD instructions are supported by all Intel/AMD processors.
If you use a SIMD instruction not supported by the processor the code is running on you’ll get a nasty panic.
It’s not obvious what set of SIMD instructions support what operations. For now, you must tediously check each method, using the comments above the method in the archsimd source.
For example, I made the mistake of assuming that archsimd.Int16x16.ToBits() (KMOVW) is supported by AVX2 since it works Int16x16 and 256-bit registers which were added for AVX2. Most methods on the Int16x16 type (such as archsimd.Int16x16.Greater()) only require AVX2 but KMOVW was added later (in AVX-512). So this code panicked:
var v1, v2 archsimd.Int16x16
...
if archsimd.X86.AVX2() { // check we have AVX2 support
gtr := v1.Greater(v2) // OK (only needs AVX2)
mask := gtr.ToBits() // PANIC (requires AVX-512)
}
This problem (as well as the necessity of build tags) will be addressed in Go, hopefully in the near future. There will be a high-level standard library package that will perform vector operations in a “portable” way. That is, there will be methods that take advantage of SIMD operations available in the architecture (at build time) and on the specific CPU (at run-time), falling back to non-SIMD code if necessary.
Secret
Certain pieces of text/data (passwords, private keys, API keys, etc) should be carefully protected. Of course, you would never write them as cleartext (unencrypted) to disk/network/etc, would you?. Even so, there are still risks even if a copy of memory (containing the cleartext) can be obtained by:
- an admin copying memory of running software
- a cracker gaining permission to do the same
- a crash that writes a core dump to disk
- memory written to a swap file
- someone physically removing memory DIMMs from the machine (and keeping them cool)
For this reason it is important that memory containing such data is cleared as soon as it is no longer required. Ideally, the cleartext should only be present in memory for milliseconds or less.
There have been some useful Go libraries on github such as memguard that tackled this problem. Now there is the runtime/secret package in the standard library that takes a different approach.
To use it just pass a function to secret.Do(). (In Go 1.26 it is an experiment so you need to set GOEXPERIMENT=runtimesecret.)
import "runtime/secret"
...
var int result
secret.Do(func() {
key := DecryptKeyFromDisk(filename)
result = Validate(key)
})
When secret.Do() returns all memory that was used by local variables of the function (such a key) have been wiped, as well as the locals of all functions in the call-tree (such as DecryptFromDisk()). This always happens, even if there is a panic.
Moreover, any heap allocated variables are also erased, but not always immediately. I recommend that any sensitive data is kept local (ie, does not leak to the heap) so that it is wiped quickly. (There are other reasons as explained in the doc. for secret.Do()).
This experiment currently only works with Linux (amd64 & arm64). On other architectures it just calls the function without any protection!
Crypto
The crypto packages in the Go standard library are world-class and well maintained, which is very important for security. As I mentioned in past posts there has been a lot of support recently added for post-quantum algorithms, some of which weren’t even mentioned in the release notes.
The new crypto/hpke package supports RFC9180 (emerging standard for Hybrid Public Key Encryption) including support for a quantum safe hybrid KEM (key encapsulation mechanism).
Also, since TLS is the backbone of Internet security, it is very important that the hybrid SecP256r1MLKEM768 and SecP384r1MLKEM1024 post-quantum key exchanges are on by default.
Language
New new() overload
Go has really nice support for creating literals of just about any type. All languages have numeric literals but Go lets you create literals for structs, maps, etc.
num := 42 // integer literal
loc := point{x:1, y:2} // struct literal
lut := dict{ "a": 10, "b": 20} // map literal
You can also create pointer literals but only for composite types.
pLoc := &point{x:1, y:2} // ptr to struct literal
pLut := &dict{ "a": 10, "b": 20} // ptr to map literal
pNum := &42 // ERROR
I always thought it was a bit of an oversight that you can’t similarly create a pointer to a basic type without first creating a temporary. In Go 1.26 there is an overload of the new() function that allows you to do just that.
pNum := new(42)
In other words, the argument to new() can now be a type (as before) or an expression. This is particularly useful for structs with pointer fields – pointers can be nil allowing you to differentiate a null value. This is used when dealing with databases, serialisation or anything that has optional values.
p1 := new(string) // type parameter - returns ptr to empty string
p2 := new(strings.Repeat("x", 10)) // value parameter - returns ptr to "xxxxxxxxxx"
p3 := new(nil) // ERROR - nil has no concrete type
Don’t forget that, although new() returns a pointer, the value pointed to is not necessarily placed on the heap. It’s up to the Go compiler’s escape analysis to determine whether the object lives – on the GC heap or somewhere else (stack).
Self-referential Generic Types
Adding generics to Go (with the goal of simplicity and efficiency) was hard and the result is that Go generics has limitations. There is usually a good reason why you can’t do things that you may be able to do with generics other languages. This is due to the tradeoffs that Go made to keep generics efficient (both at run-time and for build times) and simple to use.
Since Go 1.18, some limitations have been removed. For example, last year some great improvements were made to type inference.
In this release another improvement has been made that affected some people – generic types can now refer to themselves. This makes for greater type safety since you no longer need to use any.
Runtime
Green Tea GC
Last time I talked about the new heap manager.
The change was given the code name Green Tea GC though the changes are more about the data structures used for the heap than changes to the garbage collection strategy.
Nothing much has changed with GTGC from the Go 1.25 experiment except that it is now the default.
If you think the change is causing issues then, in Go 1.26, you can go back to the old one by setting the experiment nogreenteagc. Of course, you should file an issue, with a code example (if possible)
The GTGC was a huge change, so I was expecting something impressive from it, but I did a lot of tests in Go 1.25 (with/without greenteagc experiment turned on) and was not able to get any measureable performance improvements. The only difference I could see was that when a garbage collection runs (in the background) the runtime was grabbing fewer goroutines to do it’s work.
However, now it’s running on production servers I have seen a reduction in the size of the maximum spikes in latency of requests. I discussed this last time and there is an update in Background above.
Heap Address Randomisation
Speaking of the heap – the runtime no longer uses a fixed heap base address. This makes it harder for external malware to know where to look.
Apparently this is only relevant is you use CGO, which I try to avoid.
Tools
Go fix
Go fix is a tool that you can use to automatically upgrade your code when a new Go release makes language and library changes.
In the early days of Go (before Go 1.0) there were often breaking language changes and go fix was a big help to update code.
Nowadays, go fix does not get a lot of use, due to Go’s backward compatibility. However, it can be useful to convert code to use new features. It can “upgrade” your code to be simpler, faster, or simply to comply with the latest practices.
As it’s pretty ancient, and not used a lot, my impression was that go fix was fading away. I was surprised to find it has been completely rewritten to use the new Go analysis package that is used with go vet.
There is also a cool new “inliner” which can automatically convert deprecated functions to use new functions/calling conventions. This just entails annotating new functions with //go:fix.
Also as part of the change some old fixers have been removed.
All the fixers should be safe. They won’t change the behaviour of your code, but if you don’t trust it just run go fix ./... and review the differences
See these great Go blog posts for more: Using go fix to modernize Go code and //go:fix inline and the source-level inliner.
Goroutine Leak Profiler
Go makes concurrency easy, sometimes too easy, and a lot of Go software has undiagnosed goroutine leak(s). This is one reason I was very happy to find that synctest package can expose this issue (see Synctest - Detecting Goroutine Leaks). Unfortunately, you can only use synctest in tests since Go 1.25, but luckily there is now a new leak profiler.
Such a leak is usually caused by a goroutine that is blocked reading or writing a channel where there is nothing on the other end. Or it could be waiting on a mutex that will never be unlocked
A new profile type named goroutineleak in the runtime/pprof package can be enabled by setting GOEXPERIMENT=goroutineleakprofile.
Generating goroutine leak profiles is the same as any other profile. An easy way, especially if your code already uses a web server, is to use the net/http/pprof package - see The net/http/pprof package
Conclusion
Sorry, I’ve mainly talked about SIMD (and still didn’t mention a lot of things I tried). Undoubtedly, I’ll post some more on this later.
The archsimd package is not ready for production use unless you develop for specific X86 hardware. It is useful for me as I know the hardware that my code runs on. In general, you need to be very careful that you don’t use SIMD instructions that are not supported for all the CPUs your code can run on. Hopefully, this is addressed in Go 1.27.
I recommend sticking to AVX2, and not using AVX-512 until it is better supported.
As for the other things, there are some nice tweaks to the language and great improvements in performance, security and testing. I particularly like that Go is leading the way in quantum safe encryption.
Comments